原文:
- 🙏最近参加了几个面… - @halfrost的微博 - 微博 (weibo.com)
- Halfrost-Field/contents/Go/LRU_LFU_interview.md at master · halfrost/Halfrost-Field (github.com)

面试中 LRU / LFU 的青铜与王者
已经 0202 年了,大厂面试手撸算法题已经是标配。第一轮就遇到手撸 LRU / LFU 的几率还是挺大的。LeetCode 上 146. LRU Cache 和 460. LFU Cache,LRU 是 Medium 难度,LFU 是 Hard 难度,面试官眼里认为这 2 个问题是最最最基础的。这篇文章就来聊聊面试中 LRU / LFU 的青铜与王者。
缓存淘汰算法不仅仅只有 LRU / LFU 这两种,还有很多种,TLRU (Time aware least recently used),PLRU (Pseudo-LRU),SLRU (Segmented LRU),LFRU (Least frequent recently used),LFUDA (LFU with dynamic aging),LIRS (Low inter-reference recency set),ARC (Adaptive Replacement Cache),FIFO (First In First Out),MRU (Most recently used),LIFO (Last in first out),FILO (First in last out),CAR (Clock with adaptive replacement) 等等。感兴趣的同学可以把这每一种都用代码实现一遍。
倔强青铜
面试官可能就直接拿出 LeetCode 上这 2 道题让你来做的。在笔者拿出标准答案之前,先简单介绍一下 LRU 和 LFU 的概念。
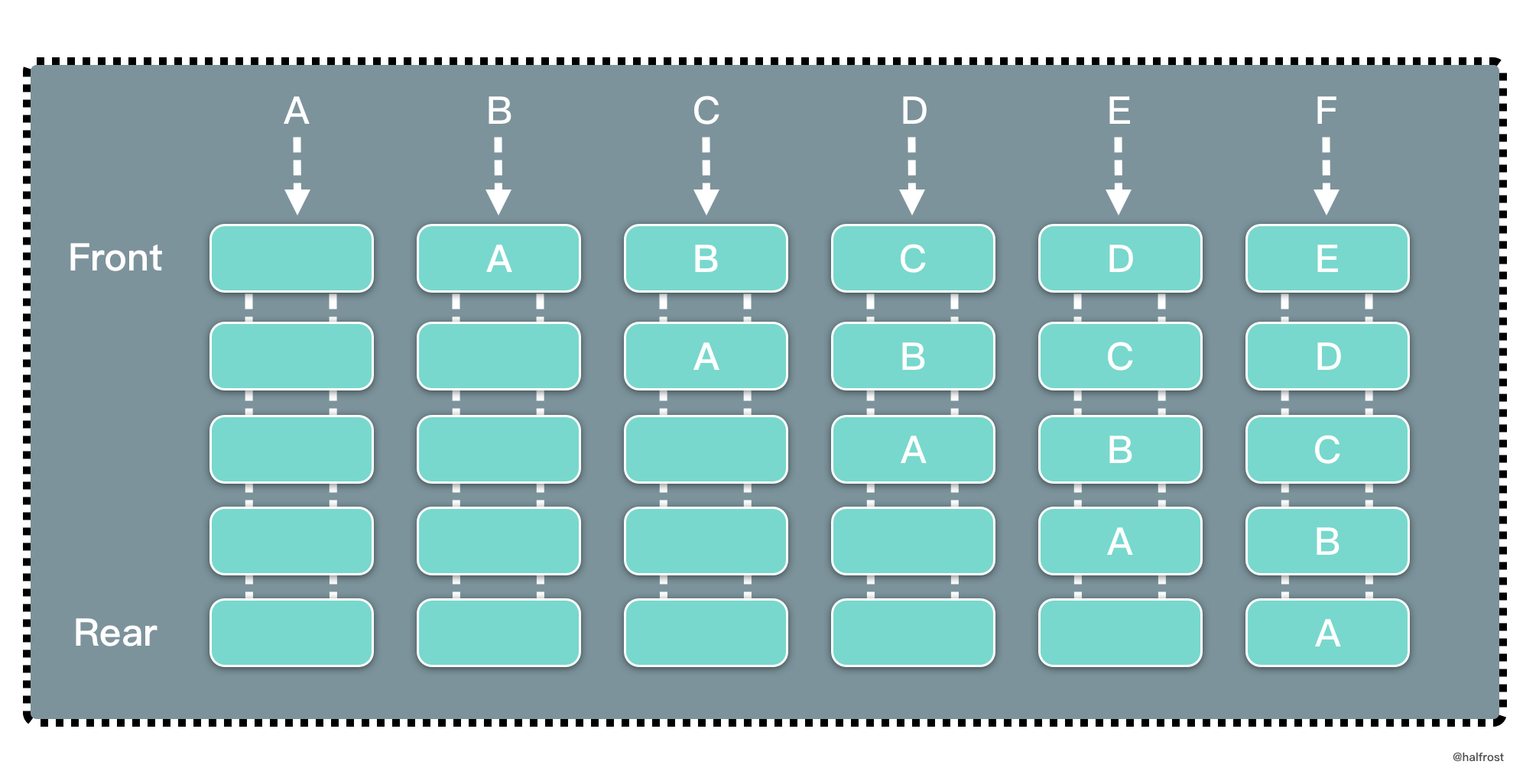
LRU 是 Least Recently Used 的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。如上图,要插入 F 的时候,此时需要淘汰掉原来的一个页面。
根据 LRU 的策略,每次都淘汰最近最久未使用的页面,所以先淘汰 A 页面。再插入 C 的时候,发现缓存中有 C 页面,这个时候需要把 C 页面放到首位,因为它被使用了。以此类推,插入 G 页面,G 页面是新页面,不在缓存中,所以淘汰掉 B 页面。插入 H 页面,H 页面是新页面,不在缓存中,所以淘汰掉 D 页面。插入 E 的时候,发现缓存中有 E 页面,这个时候需要把 E 页面放到首位。插入 I 页面,I 页面是新页面,不在缓存中,所以淘汰掉 F 页面。
可以发现,LRU 更新和插入新页面都发生在链表首,删除页面都发生在链表尾。
LRU 要求查询尽量高效,O (1) 内查询。那肯定选用 map 查询。修改,删除也要尽量 O (1) 完成。搜寻常见的数据结构,链表,栈,队列,树,图。树和图排除,栈和队列无法任意查询中间的元素,也排除。所以选用链表来实现。但是如果选用单链表,删除这个结点,需要 O (n) 遍历一遍找到前驱结点。所以选用双向链表,在删除的时候也能 O (1) 完成。
由于 Go 的 container 包中的 list 底层实现是双向链表,所以可以直接复用这个数据结构。定义 LRUCache 的数据结构如下:
import "container/list"
type LRUCache struct {
Cap int
Keys map[int]*list.Element
List *list.List
}
type pair struct {
K, V int
}
func Constructor(capacity int) LRUCache {
return LRUCache{
Cap: capacity,
Keys: make(map[int]*list.Element),
List: list.New(),
}
}
这里需要解释 2 个问题,list 中的值存的是什么?pair 这个结构体有什么用?
type Element struct {
// Next and previous pointers in the doubly-linked list of elements.
// To simplify the implementation, internally a list l is implemented
// as a ring, such that &l.root is both the next element of the last
// list element (l.Back()) and the previous element of the first list
// element (l.Front()).
next, prev *Element
// The list to which this element belongs.
list *List
// The value stored with this element.
Value interface{}
}在 container/list 中,这个双向链表的每个结点的类型是 Element。Element 中存了 4 个值,前驱和后继结点,双向链表的头结点,value 值。这里的 value 是 interface 类型。笔者在这个 value 里面存了 pair 这个结构体。这就解释了 list 里面存的是什么数据。
为什么要存 pair 呢?单单指存 v 不行么,为什么还要存一份 key ?原因是在 LRUCache 执行删除操作的时候,需要维护 2 个数据结构,一个是 map,一个是双向链表。在双向链表中删除淘汰出去的 value,在 map 中删除淘汰出去 value 对应的 key。如果在双向链表的 value 中不存储 key,那么再删除 map 中的 key 的时候有点麻烦。如果硬要实现,需要先获取到双向链表这个结点 Element 的地址。然后遍历 map,在 map 中找到存有这个 Element 元素地址对应的 key,再删除。这样做时间复杂度是 O (n),做不到 O (1)。所以双向链表中的 Value 需要存储这个 pair。
LRUCache 的 Get 操作很简单,在 map 中直接读取双向链表的结点。如果 map 中存在,将它移动到双向链表的表头,并返回它的 value 值,如果 map 中不存在,返回 -1。
func (c *LRUCache) Get(key int) int {
if el, ok := c.Keys[key]; ok {
c.List.MoveToFront(el)
return el.Value.(pair).V
}
return -1
}LRUCache 的 Put 操作也不难。先查询 map 中是否存在 key,如果存在,更新它的 value,并且把该结点移到双向链表的表头。如果 map 中不存在,新建这个结点加入到双向链表和 map 中。最后别忘记还需要维护双向链表的 cap,如果超过 cap,需要淘汰最后一个结点,双向链表中删除这个结点,map 中删掉这个结点对应的 key。
func (c *LRUCache) Put(key int, value int) {
if el, ok := c.Keys[key]; ok {
el.Value = pair{K: key, V: value}
c.List.MoveToFront(el)
} else {
el := c.List.PushFront(pair{K: key, V: value})
c.Keys[key] = el
}
if c.List.Len() > c.Cap {
el := c.List.Back()
c.List.Remove(el)
delete(c.Keys, el.Value.(pair).K)
}
}
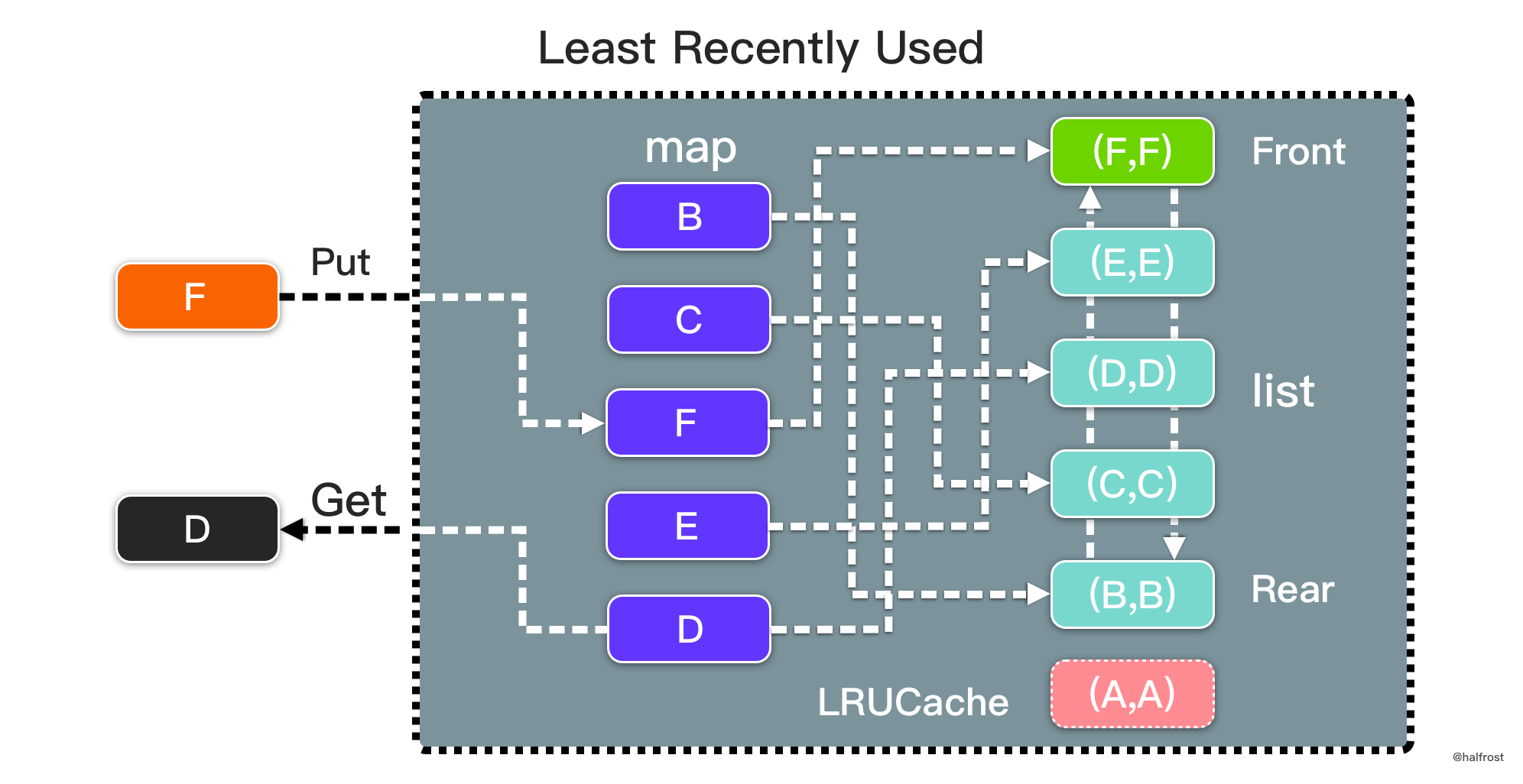
总结,LRU 是由一个 map 和一个双向链表组成的数据结构。map 中 key 对应的 value 是双向链表的结点。双向链表中存储 key-value 的 pair。双向链表表首更新缓存,表尾淘汰缓存。如下图:
提交代码以后,成功通过所有测试用例。
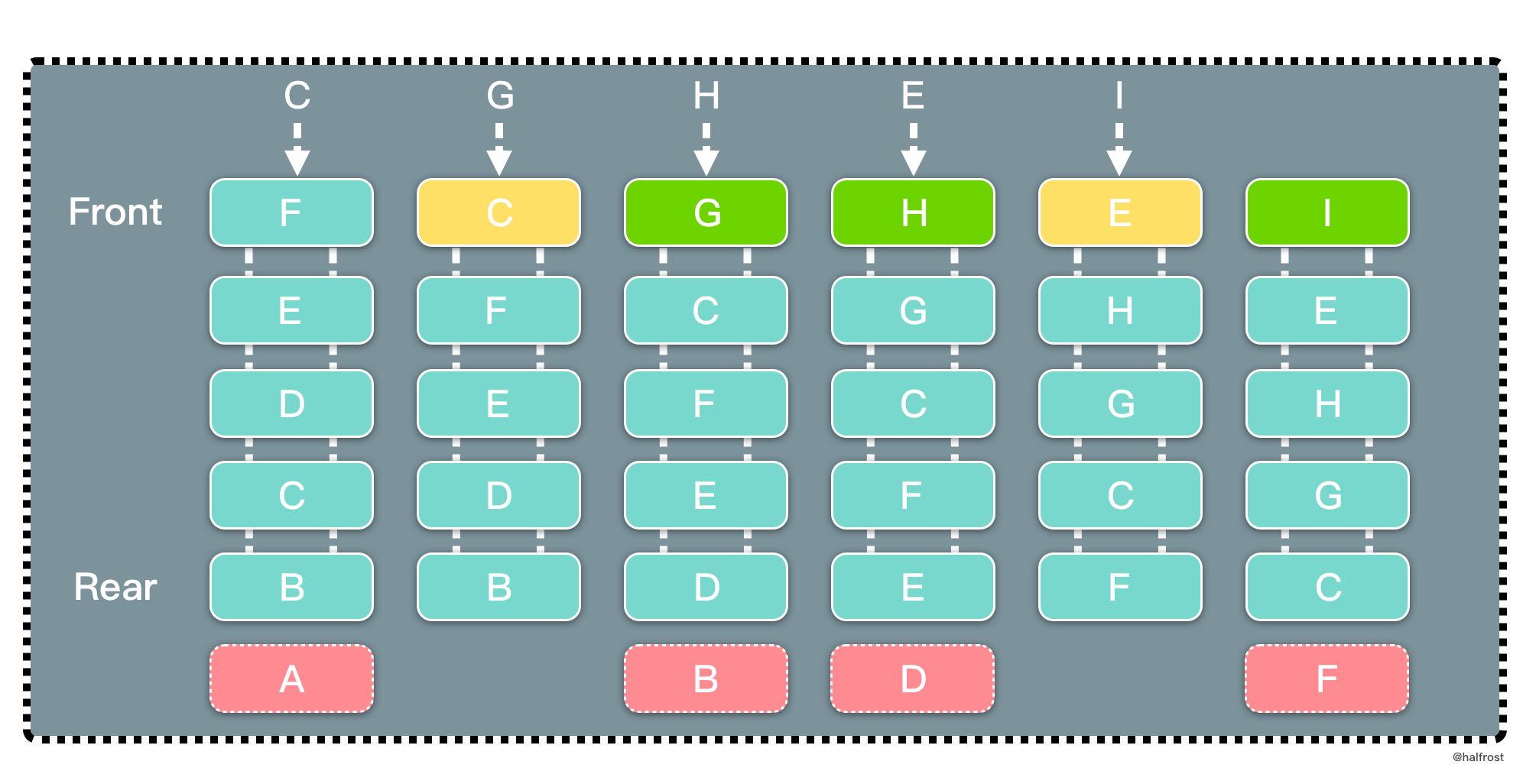
LFU 是 Least Frequently Used 的缩写,即最不经常最少使用,也是一种常用的页面置换算法,选择访问计数器最小的页面予以淘汰。如下图,缓存中每个页面带一个访问计数器。
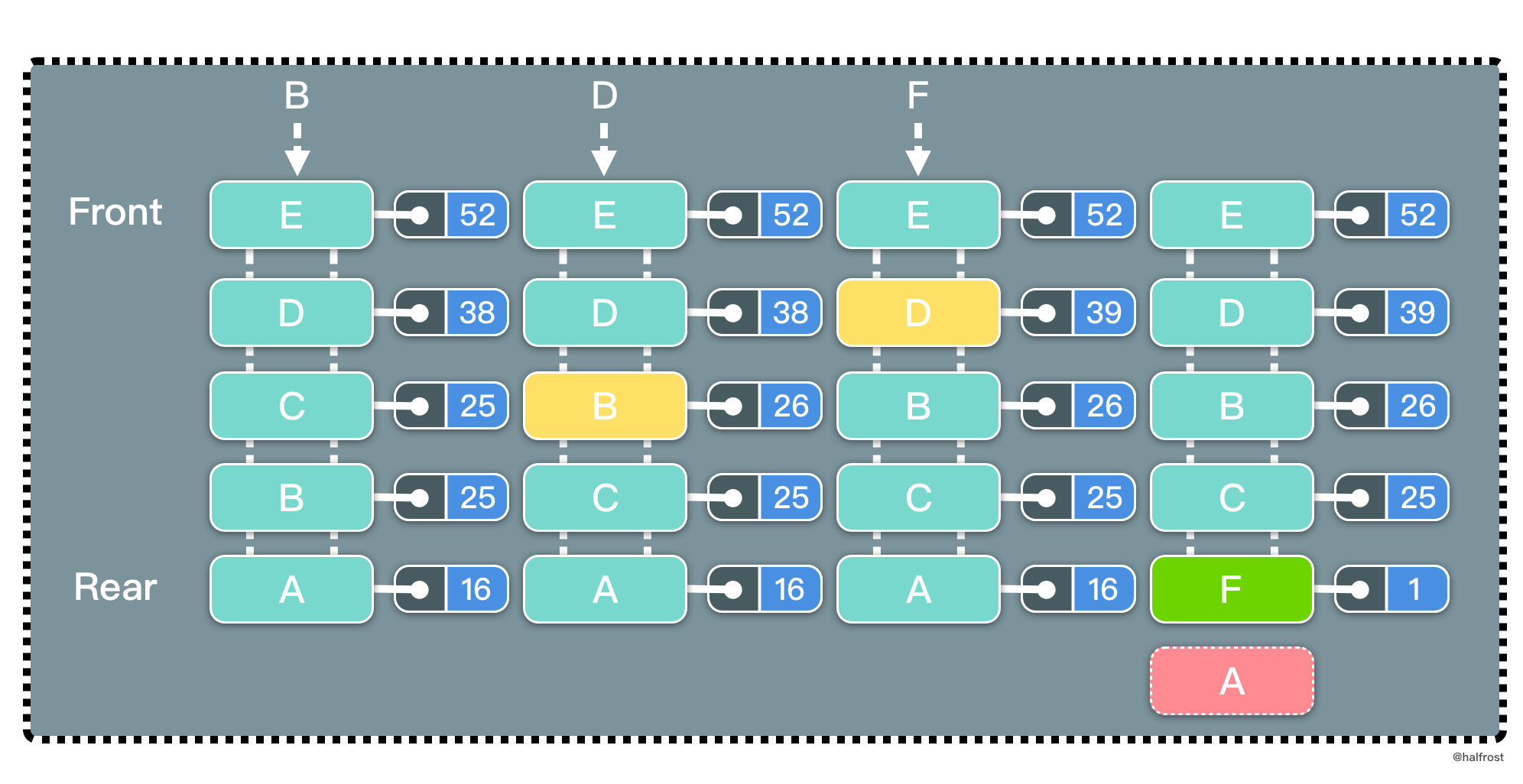
根据 LFU 的策略,每访问一次都要更新访问计数器。当插入 B 的时候,发现缓存中有 B,所以增加访问计数器的计数,并把 B 移动到访问计数器从大到小排序的地方。再插入 D,同理先更新计数器,再移动到它排序以后的位置。当插入 F 的时候,缓存中不存在 F,所以淘汰计数器最小的页面的页面,所以淘汰 A 页面。此时 F 排在最下面,计数为 1。
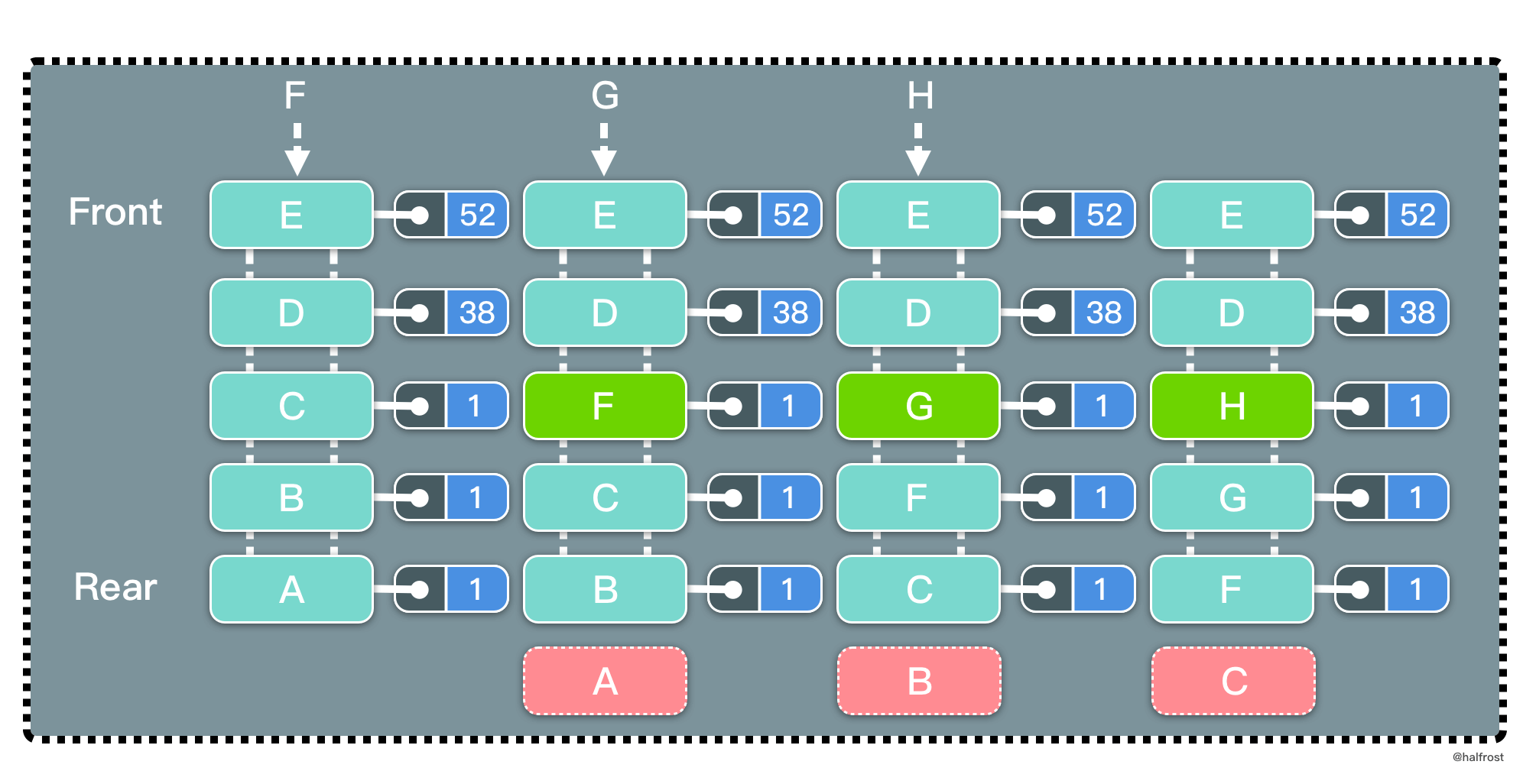
这里有一个比 LRU 特别的地方。如果淘汰的页面访问次数有多个相同的访问次数,选择最靠尾部的。如上图中,A、B、C 三者的访问次数相同,都是 1 次。要插入 F,F 不在缓存中,此时要淘汰 A 页面。F 是新插入的页面,访问次数为 1,排在 C 的前面。也就是说相同的访问次数,按照新旧顺序排列,淘汰掉最旧的页面。这一点是和 LRU 最大的不同的地方。
可以发现,LFU 更新和插入新页面可以发生在链表中任意位置,删除页面都发生在表尾。
LFU 同样要求查询尽量高效,O (1) 内查询。依旧选用 map 查询。修改和删除也需要 O (1) 完成,依旧选用双向链表,继续复用 container 包中的 list 数据结构。LFU 需要记录访问次数,所以每个结点除了存储 key,value,需要再多存储 frequency 访问次数。
还有 1 个问题需要考虑,一个是如何按频次排序?相同频次,按照先后顺序排序。如果你开始考虑排序算法的话,思考方向就偏离最佳答案了。排序至少 O (nlogn)。重新回看 LFU 的工作原理,会发现它只关心最小频次。其他频次之间的顺序并不关心。所以不需要排序。用一个 min 变量保存最小频次,淘汰时读取这个最小值能找到要删除的结点。相同频次按照先后顺序排列,这个需求还是用双向链表实现,双向链表插入的顺序体现了结点的先后顺序。相同频次对应一个双向链表,可能有多个相同频次,所以可能有多个双向链表。用一个 map 维护访问频次和双向链表的对应关系。删除最小频次时,通过 min 找到最小频次,然后再这个 map 中找到这个频次对应的双向链表,在双向链表中找到最旧的那个结点删除。这就解决了 LFU 删除操作。
LFU 的更新操作和 LRU 类似,也需要用一个 map 保存 key 和双向链表结点的映射关系。这个双向链表结点中存储的是 key-value-frequency 三个元素的元组。这样通过结点中的 key 和 frequency 可以反过来删除 map 中的 key。
定义 LFUCache 的数据结构如下:
import "container/list"
type LFUCache struct {
nodes map[int]*list.Element
lists map[int]*list.List
capacity int
min int
}
type node struct {
key int
value int
frequency int
}
func Constructor(capacity int) LFUCache {
return LFUCache{nodes: make(map[int]*list.Element),
lists: make(map[int]*list.List),
capacity: capacity,
min: 0,
}
}
LFUCache 的 Get 操作涉及更新 frequency 值和 2 个 map。在 nodes map 中通过 key 获取到结点信息。在 lists 删除结点当前 frequency 结点。删完以后 frequency ++。新的 frequency 如果在 lists 中存在,添加到双向链表表首,如果不存在,需要新建一个双向链表并把当前结点加到表首。再更新双向链表结点作为 value 的 map。最后更新 min 值,判断老的 frequency 对应的双向链表中是否已经为空,如果空了,min++。
func (this *LFUCache) Get(key int) int {
value, ok := this.nodes[key]
if !ok {
return -1
}
currentNode := value.Value.(*node)
this.lists[currentNode.frequency].Remove(value)
currentNode.frequency++
if _, ok := this.lists[currentNode.frequency]; !ok {
this.lists[currentNode.frequency] = list.New()
}
newList := this.lists[currentNode.frequency]
newNode := newList.PushFront(currentNode)
this.nodes[key] = newNode
if currentNode.frequency-1 == this.min && this.lists[currentNode.frequency-1].Len() == 0 {
this.min++
}
return currentNode.value
}
LFU 的 Put 操作逻辑稍微多一点。先在 nodes map 中查询 key 是否存在,如果存在,获取这个结点,更新它的 value 值,然后手动调用一次 Get 操作,因为下面的更新逻辑和 Get 操作一致。如果 map 中不存在,接下来进行插入或者删除操作。判断 capacity 是否装满,如果装满,执行删除操作。在 min 对应的双向链表中删除表尾的结点,对应的也要删除 nodes map 中的键值。
由于新插入的页面访问次数一定为 1,所以 min 此时置为 1。新建结点,插入到 2 个 map 中。
func (this *LFUCache) Put(key int, value int) {
if this.capacity == 0 {
return
}
// 如果存在,更新访问次数
if currentValue, ok := this.nodes[key]; ok {
currentNode := currentValue.Value.(*node)
currentNode.value = value
this.Get(key)
return
}
// 如果不存在且缓存满了,需要删除
if this.capacity == len(this.nodes) {
currentList := this.lists[this.min]
backNode := currentList.Back()
delete(this.nodes, backNode.Value.(*node).key)
currentList.Remove(backNode)
}
// 新建结点,插入到 2 个 map 中
this.min = 1
currentNode := &node{
key: key,
value: value,
frequency: 1,
}
if _, ok := this.lists[1]; !ok {
this.lists[1] = list.New()
}
newList := this.lists[1]
newNode := newList.PushFront(currentNode)
this.nodes[key] = newNode
}
总结,LFU 是由两个 map 和一个 min 指针组成的数据结构。一个 map 中 key 存的是访问次数,对应的 value 是一个个的双向链表,此处双向链表的作用是在相同频次的情况下,淘汰表尾最旧的那个页面。另一个 map 中 key 对应的 value 是双向链表的结点,结点中比 LRU 多存储了一个访问次数的值,即结点中存储 key-value-frequency 的元组。此处双向链表的作用和 LRU 是类似的,可以根据 map 中的 key 更新双向链表结点中的 value 和 frequency 的值,也可以根据双向链表结点中的 key 和 frequency 反向更新 map 中的对应关系。如下图:
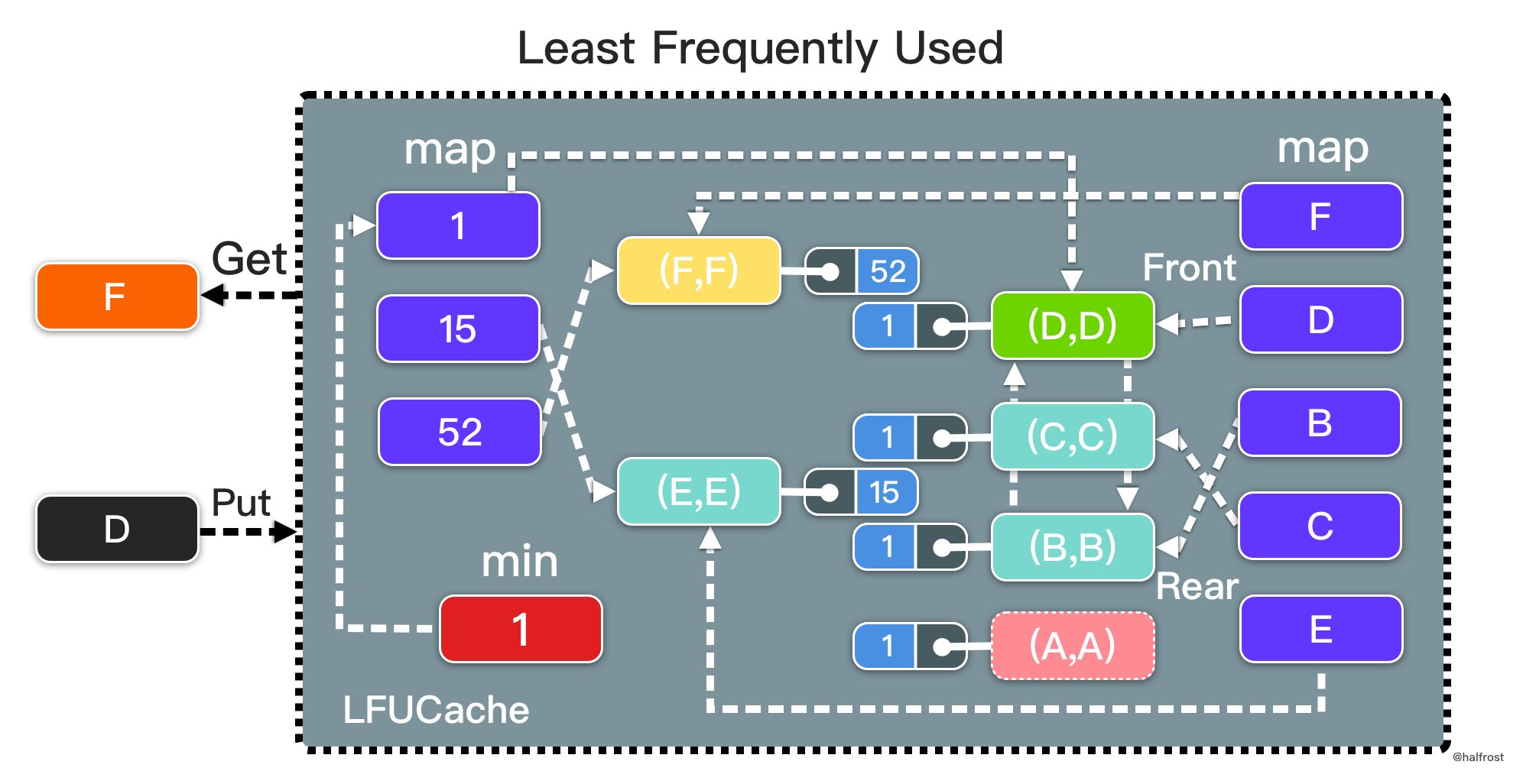
提交代码以后,成功通过所有测试用例。
荣耀黄金
面试中如果给出了上面青铜的答案,可能会被追问,“还有没有其他解法?” 虽然目前青铜的答案已经是最优解了,但是面试官还想考察多解。
先考虑 LRU。数据结构上想不到其他解法了,但从打败的百分比上,看似还有常数的优化空间。笔者反复思考,觉得可能导致运行时间变长的地方是在 interface{} 类型推断,其他地方已无优化的空间。手写一个双向链表提交试试,代码如下:
type LRUCache struct {
head, tail *Node
keys map[int]*Node
capacity int
}
type Node struct {
key, val int
prev, next *Node
}
func ConstructorLRU(capacity int) LRUCache {
return LRUCache{keys: make(map[int]*Node), capacity: capacity}
}
func (this *LRUCache) Get(key int) int {
if node, ok := this.keys[key]; ok {
this.Remove(node)
this.Add(node)
return node.val
}
return -1
}
func (this *LRUCache) Put(key int, value int) {
if node, ok := this.keys[key]; ok {
node.val = value
this.Remove(node)
this.Add(node)
return
} else {
node = &Node{key: key, val: value}
this.keys[key] = node
this.Add(node)
}
if len(this.keys) > this.capacity {
delete(this.keys, this.tail.key)
this.Remove(this.tail)
}
}
func (this *LRUCache) Add(node *Node) {
node.prev = nil
node.next = this.head
if this.head != nil {
this.head.prev = node
}
this.head = node
if this.tail == nil {
this.tail = node
this.tail.next = nil
}
}
func (this *LRUCache) Remove(node *Node) {
if node == this.head {
this.head = node.next
if node.next != nil {
node.next.prev = nil
}
node.next = nil
return
}
if node == this.tail {
this.tail = node.prev
node.prev.next = nil
node.prev = nil
return
}
node.prev.next = node.next
node.next.prev = node.prev
}
提交以后还真的 100% 了。
上述代码实现的 LRU 本质并没有优化,只是换了一个写法,没有用 container 包而已。
LFU 的另外一个思路是利用 Index Priority Queue 这个数据结构。别被名字吓到,Index Priority Queue = map + Priority Queue,仅此而已。
利用 Priority Queue 维护一个最小堆,堆顶是访问次数最小的元素。map 中的 value 存储的是优先队列中结点。
import "container/heap"
type LFUCache struct {
capacity int
pq PriorityQueue
hash map[int]*Item
counter int
}
func Constructor(capacity int) LFUCache {
lfu := LFUCache{
pq: PriorityQueue{},
hash: make(map[int]*Item, capacity),
capacity: capacity,
}
return lfu
}
Get 和 Put 操作要尽量的快,有 2 个问题需要解决。当访问次数相同时,如何删除掉最久的元素?当元素的访问次数发生变化时,如何快速调整堆?为了解决这 2 个问题,定义如下的数据结构:
// An Item is something we manage in a priority queue.
type Item struct {
value int // The value of the item; arbitrary.
key int
frequency int // The priority of the item in the queue.
count int // use for evicting the oldest element
// The index is needed by update and is maintained by the heap.Interface methods.
index int // The index of the item in the heap.
}
堆中的结点存储这 5 个值。count 值用来决定哪个是最老的元素,类似一个操作时间戳。index 值用来 re-heapify 调整堆的。接下来实现 PriorityQueue 的方法。
// A PriorityQueue implements heap.Interface and holds Items.
type PriorityQueue []*Item
func (pq PriorityQueue) Len() int { return len(pq) }
func (pq PriorityQueue) Less(i, j int) bool {
// We want Pop to give us the highest, not lowest, priority so we use greater than here.
if pq[i].frequency == pq[j].frequency {
return pq[i].count < pq[j].count
}
return pq[i].frequency < pq[j].frequency
}
func (pq PriorityQueue) Swap(i, j int) {
pq[i], pq[j] = pq[j], pq[i]
pq[i].index = i
pq[j].index = j
}
func (pq *PriorityQueue) Push(x interface{}) {
n := len(*pq)
item := x.(*Item)
item.index = n
*pq = append(*pq, item)
}
func (pq *PriorityQueue) Pop() interface{} {
old := *pq
n := len(old)
item := old[n-1]
old[n-1] = nil // avoid memory leak
item.index = -1 // for safety
*pq = old[0 : n-1]
return item
}
// update modifies the priority and value of an Item in the queue.
func (pq *PriorityQueue) update(item *Item, value int, frequency int, count int) {
item.value = value
item.count = count
item.frequency = frequency
heap.Fix(pq, item.index)
}在 Less () 方法中,frequency 从小到大排序,frequency 相同的,按 count 从小到大排序。按照优先队列建堆规则,可以得到,frequency 最小的在堆顶,相同的 frequency,count 最小的越靠近堆顶。
在 Swap () 方法中,记得要更新 index 值。在 Push () 方法中,插入时队列的长度即是该元素的 index 值,此处也要记得更新 index 值。update () 方法调用 Fix () 函数。Fix () 函数比先 Remove () 再 Push () 一个新的值,花销要小。所以此处调用 Fix () 函数,这个操作的时间复杂度是 O (log n)。
这样就维护了最小 Index Priority Queue。Get 操作非常简单:
func (this *LFUCache) Get(key int) int {
if this.capacity == 0 {
return -1
}
if item, ok := this.hash[key]; ok {
this.counter++
this.pq.update(item, item.value, item.frequency+1, this.counter)
return item.value
}
return -1
}
在 hashmap 中查询 key,如果存在,counter 时间戳累加,调用 Priority Queue 的 update 方法,调整堆。
func (this *LFUCache) Put(key int, value int) {
if this.capacity == 0 {
return
}
this.counter++
// 如果存在,增加 frequency,再调整堆
if item, ok := this.hash[key]; ok {
this.pq.update(item, value, item.frequency+1, this.counter)
return
}
// 如果不存在且缓存满了,需要删除。在 hashmap 和 pq 中删除。
if len(this.pq) == this.capacity {
item := heap.Pop(&this.pq).(*Item)
delete(this.hash, item.key)
}
// 新建结点,在 hashmap 和 pq 中添加。
item := &Item{
value: value,
key: key,
count: this.counter,
}
heap.Push(&this.pq, item)
this.hash[key] = item
}用最小堆实现的 LFU,Put 时间复杂度是 O (capacity),Get 时间复杂度是 O (capacity),不及 2 个 map 实现的版本。巧的是最小堆的版本居然打败了 100%。
提交以后,LRU 和 LFU 都打败了 100%。上述代码都封装好了,完整代码在 LeetCode-Go 中,讲解也更新到了《LeetCode Cookbook》第三章的第三节 LRUCache 和第四节 LFUCache 中。LRU 的最优解是 map + 双向链表,LFU 的最优解是 2 个 map + 多个双向链表。其实热身刚刚结束,接下来才是本文的重点。
最强王者
在面试者回答出黄金级的问题了以后,面试官可能会继续追问一个更高级的问题。“如何实现一个高并发且线程安全的 LRU 呢?”。遇到这个问题,上文讨论的代码模板就失效了。要想做到高并发,需要考虑 2 点,第一点内存分配与回收 GC 一定要快,最好是 Zero GC 开销,第二点执行操作耗时最少。详细的,由于要做到高并发,瞬间的 TPS 可能会很大,所以要最快的分配内存,开辟新的内存空间。垃圾回收也不能慢,否则内存会暴涨。针对 LRU / LFU 这个问题,执行的操作是 get 和 set,耗时需要最少。耗时高了,系统吞吐率会受到严重影响,TPS 上不去了。再者,在高并发的场景中,一定会保证线程安全。这里就需要用到锁。最简单的选用读写锁。以下举例以 LRUCache 为例。LFUCache 原理类似。(以下代码先给出改造新增的部分,最后再给出完整版)
type LRUCache struct {
sync.RWMutex
}
func (c *LRUCache) Get(key int) int {
c.RLock()
defer c.RUnlock()
……
}
func (c *LRUCache) Put(key int, value int) {
c.Lock()
defer c.Unlock()
……
}
上述代码虽然能保证线程安全,但是并发量并不高。因为在 Put 操作中,写锁会阻碍读锁,这里会锁住。接下来的优化思路很清晰,拆分大锁,让写锁尽可能的少阻碍读锁。一句话就是将锁颗粒化。
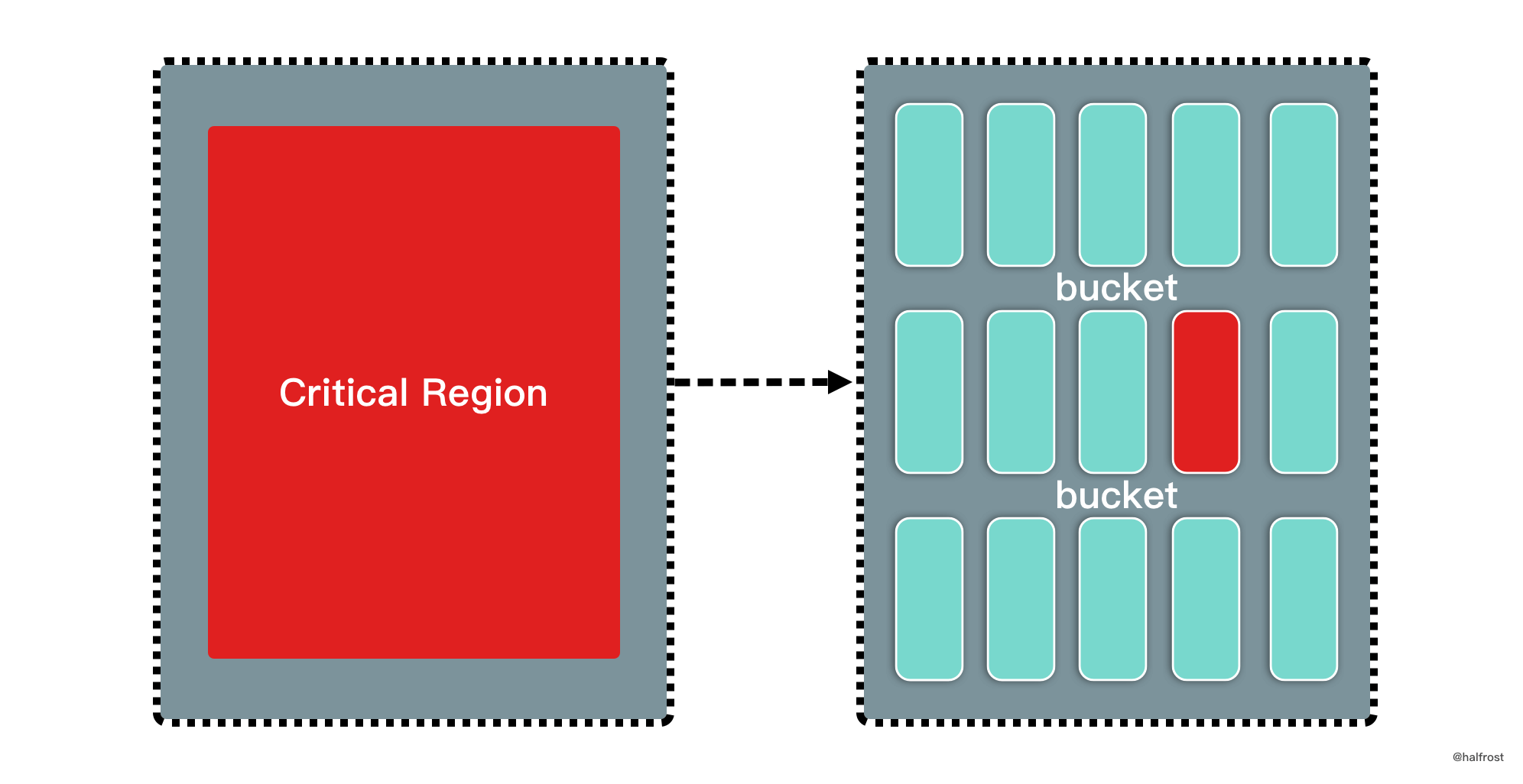
如上图,将一个大的临界区拆分成一个个小的临界区。代码如下:
type LRUCache struct {
sync.RWMutex
shards map[int]*LRUCacheShard
}
type LRUCacheShard struct {
Cap int
Keys map[int]*list.Element
List *list.List
sync.RWMutex
}
func (c *LRUCache) Get(key int) int {
shard, ok := c.GetShard(key, false)
if ok == false {
return -1
}
shard.RLock()
defer shard.RUnlock()
……
}
func (c *LRUCache) Put(key int, value int) {
shard, _ := c.GetShard(key, true)
shard.Lock()
defer shard.Unlock()
……
}
func (c *LRUCache) GetShard(key int, create bool) (shard *LRUCacheShard, ok bool) {
hasher := sha1.New()
hasher.Write([]byte(key))
shardKey := fmt.Sprintf("%x", hasher.Sum(nil))[0:2]
c.lock.RLock()
shard, ok = c.shards[shardKey]
c.lock.RUnlock()
if ok || !create {
return
}
//only time we need to write lock
c.lock.Lock()
defer c.lock.Unlock()
//check again in case the group was created in this short time
shard, ok = c.shards[shardKey]
if ok {
return
}
shard = &LRUCacheShard{
Keys: make(map[int]*list.Element),
List: list.New(),
}
c.shards[shardKey] = shard
ok = true
return
}
通过上述的改造,利用哈希把原来的 LRUCache 分为了 256 个分片 (2^8)。并且写锁锁住只发生在分片不存在的时候。一旦分片被创建了,之后都是读锁。这里依旧是小瓶颈,继续优化,消除掉这里的写锁。优化代码很简单,在创建的时候创建所有分片。
func New(capacity int) LRUCache {
shards := make(map[string]*LRUCacheShard, 256)
for i := 0; i < 256; i++ {
shards[fmt.Sprintf("%02x", i)] = &LRUCacheShard{
Cap: capacity,
Keys: make(map[int]*list.Element),
List: list.New(),
}
}
return LRUCache{
shards: shards,
}
}
func (c *LRUCache) Get(key int) int {
shard := c.GetShard(key)
shard.RLock()
defer shard.RUnlock()
……
}
func (c *LRUCache) Put(key int, value int) {
shard := c.GetShard(key)
shard.Lock()
defer shard.Unlock()
……
}
func (c *LRUCache) GetShard(key int) (shard *LRUCacheShard) {
hasher := sha1.New()
hasher.Write([]byte(key))
shardKey := fmt.Sprintf("%x", hasher.Sum(nil))[0:2]
return c.shards[shardKey]
}
到这里,大的临界区已经被拆分成细颗粒度了。在细粒度的锁内部,还包含双链表结点的操作,对结点的操作涉及到锁竞争。成熟的缓存系统如 memcached,使用的是全局的 LRU 链表锁,而 Redis 是单线程的所以不需要考虑并发的问题。回到 LRU,每个 Get 操作需要读取 key 值对应的 value,需要读锁。与此同时,Get 操作也涉及到移动最近最常使用的结点,需要写锁。Set 操作只涉及写锁。需要注意的一点,Get 和 Set 先后执行顺序非常关键。例如,先 get 一个不存在的 key,返回 nil,再 set 这个 key。如果先 set 这个 key,再 get 这个 key,返回的就是不是 nil,而是对应的 value。所以在保证锁安全 (不发生死锁)的情况下,还需要保证每个操作时序的正确性。能同时满足这 2 个条件的非带缓冲的 channel 莫属。先来看看消费 channel 通道里面数据的处理逻辑:
func (c *CLRUCache) doMove(el *list.Element) bool {
if el.Value.(Pair).cmd == MoveToFront {
c.list.MoveToFront(el)
return false
}
newel := c.list.PushFront(el.Value.(Pair))
c.bucket(el.Value.(Pair).key).update(el.Value.(Pair).key, newel)
return true
}还值得一提的是,get 和 set 的写操作有 2 种类型,一种是 MoveToFront,另外一种是当结点不存在的时候,需要先创建一个新的结点,并移动到头部。这个操作即 PushFront。笔者这里在结点中加入了 cmd 标识,默认值是 MoveToFront。
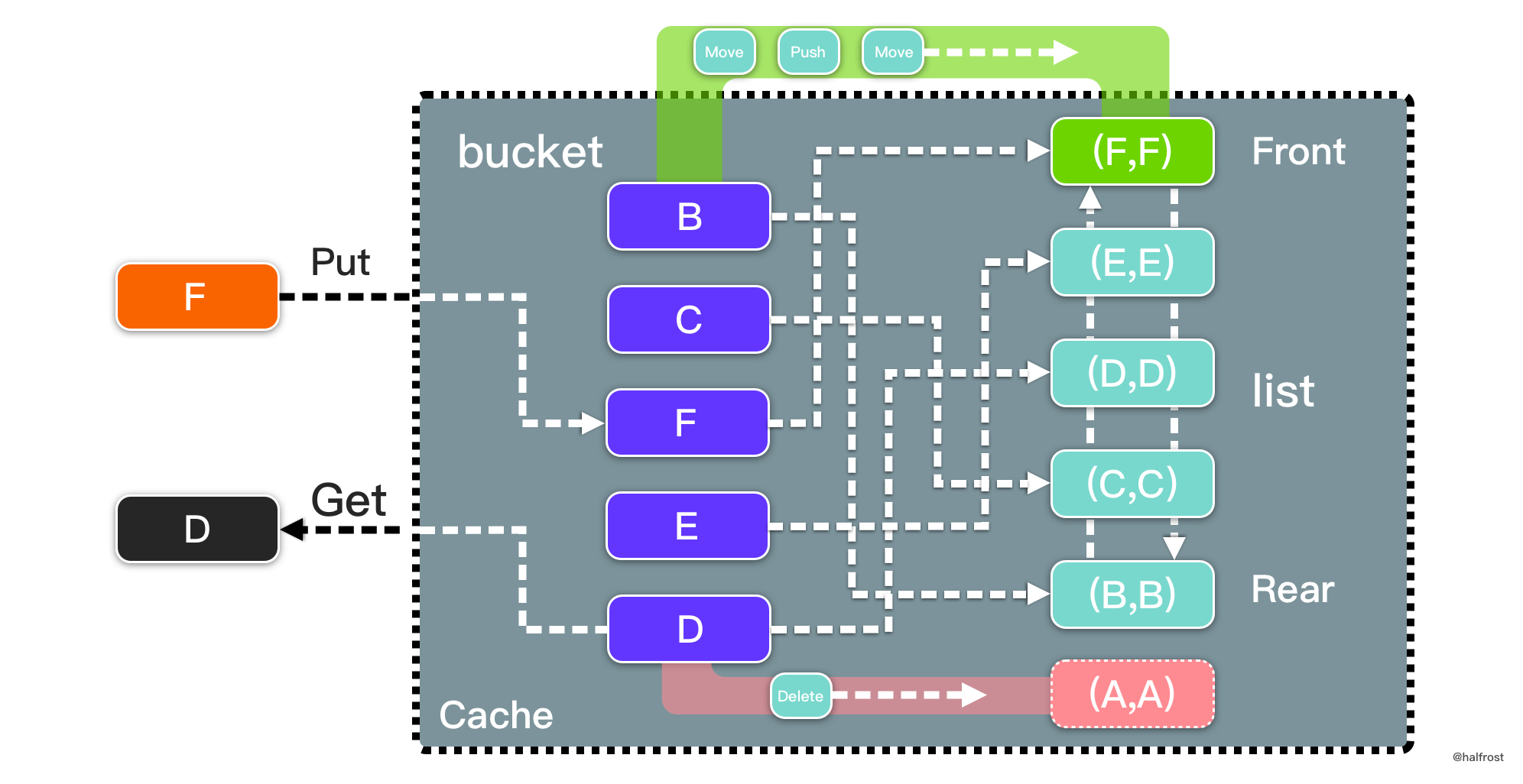
目前为止,下一步的优化思路确定使用带缓冲的 channel 了。用几个呢?答案是用 2 个。除去上面讨论的写入操作,还要管理 remove 操作。由于 LRU 逻辑的特殊性,它保证了移动结点和移除结点一定分开在双链表两端。也就是说在双链表两边同时操作,相互不影响。双链表的临界区范围可以进一步的缩小,可以缩小到结点级。最终方案就定下来了。用 2 个带缓冲的 channel,分别处理移动结点和删除结点,这两个 channel 可以在同一个协程中一起处理,互不影响。
func (c *CLRUCache) worker() {
defer close(c.control)
for {
select {
case el, ok := <-c.movePairs:
if ok == false {
goto clean
}
if c.doMove(el) && c.list.Len() > c.cap {
el := c.list.Back()
c.list.Remove(el)
c.bucket(el.Value.(Pair).key).delete(el.Value.(Pair).key)
}
case el := <-c.deletePairs:
c.list.Remove(el)
case control := <-c.control:
switch msg := control.(type) {
case clear:
for _, bucket := range c.buckets {
bucket.clear()
}
c.list = list.New()
msg.done <- struct{}{}
}
}
}
clean:
for {
select {
case el := <-c.deletePairs:
c.list.Remove(el)
default:
close(c.deletePairs)
return
}
}
}最终完整的代码放在这里了。最后简单的跑一下 Benchmark 看看性能如何。
以下性能测试部分是面试结束后,笔者测试的。面试时写完代码,并没有当场 Benchmark。
go test -bench BenchmarkGetAndPut1 -run none -benchmem -cpuprofile cpuprofile.out -memprofile memprofile.out -cpu=8goos: darwin
goarch: amd64
pkg: github.com/halfrost/LeetCode-Go/template
BenchmarkGetAndPut1-8 368578 2474 ns/op 530 B/op 14 allocs/op
PASS
ok github.com/halfrost/LeetCode-Go/template 1.022s
BenchmarkGetAndPut 2 只是简单的全局加锁,会有死锁的情况。可以看到方案一的性能还行,368578 次循环平均出来的结果,平均一次 Get/Set 需要 2474 ns,那么 TPS 大约是 300 K/s,可以满足一般高并发的需求。
最后看看这个版本下的 CPU 消耗情况,符合预期:
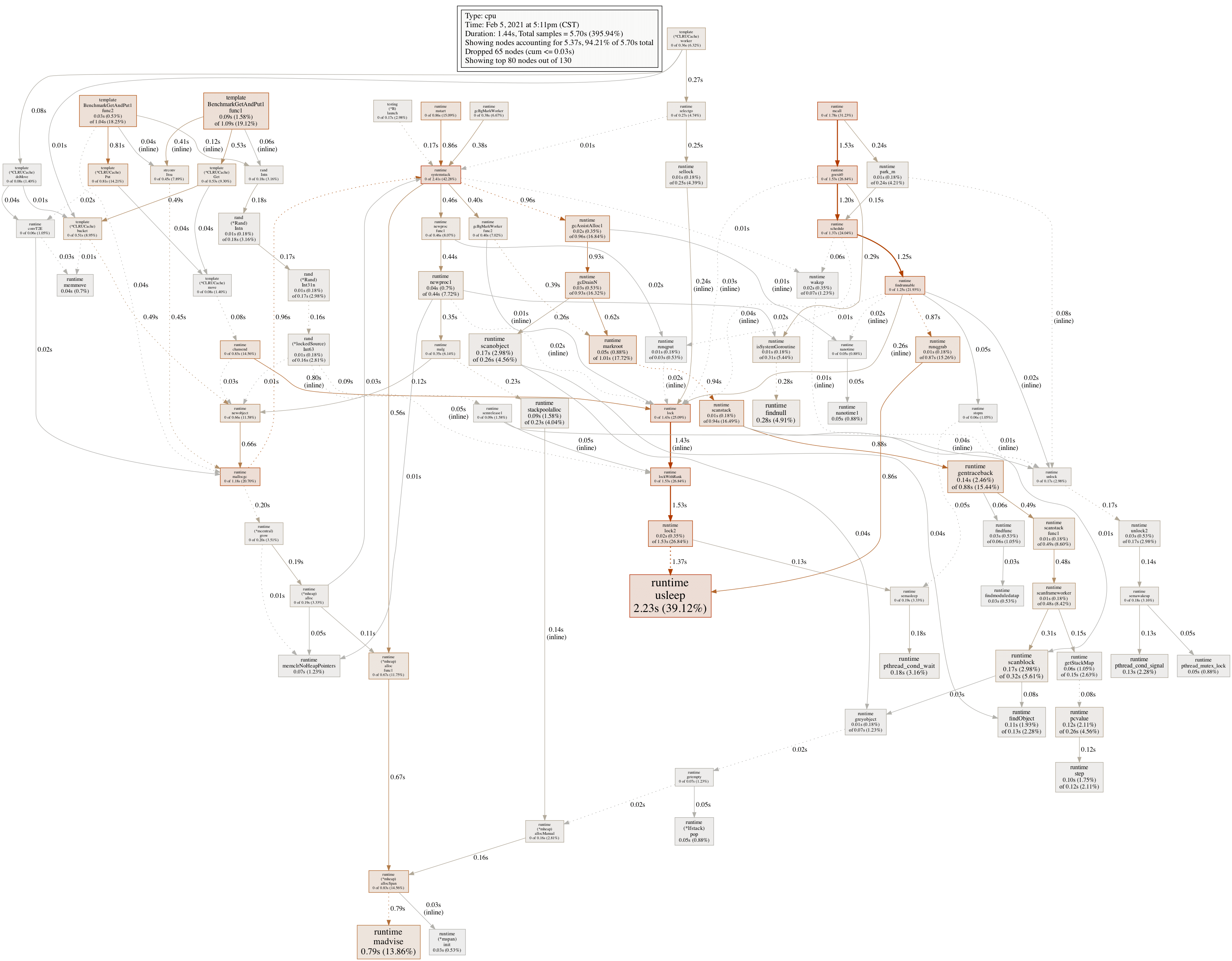
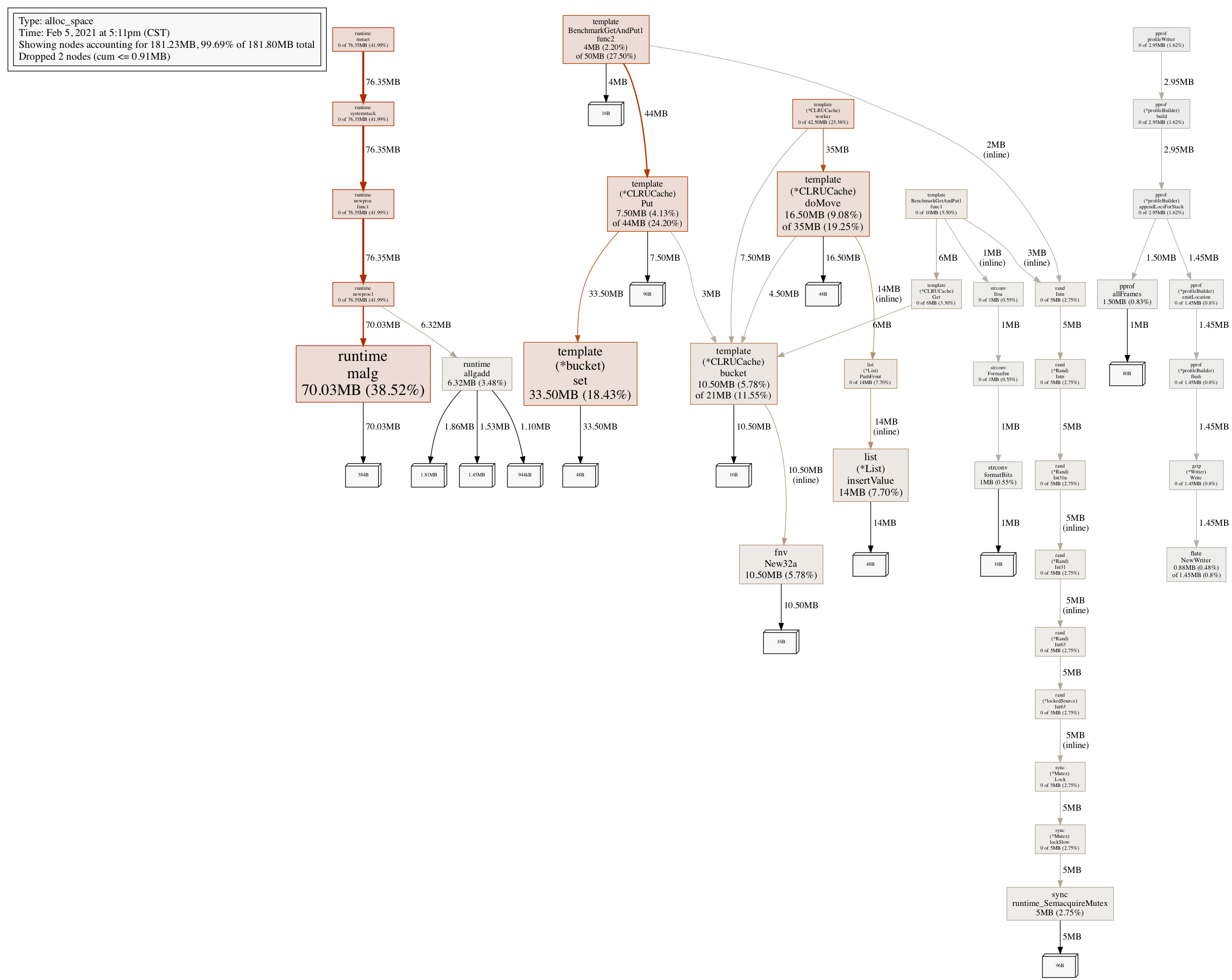
内存分配情况,也符合预期:
至此,你已经是王者了。
荣耀王者
这里是附加题部分。面试官问到这里就和 LRU/LFU 直接关系不大了,更多的考察的是如何设计一个高并发的 Cache。笔者之所以在这篇文章最后提一笔,是想给读者扩展思维。面试官会针对你给出的高并发版的 LRU 继续问,“你觉得你写的这个版本缺点在哪里?和真正的 Cache 比,还有哪些欠缺?”
在上一节“最强王者”中,粗略的实现了一个高并发的 LRU。但是这个方案还不是最完美的。当高并发高到一个临界值的时候,即 Get 请求的速度达到 Go 内存回收速度的几百倍,几万倍的时候。bucket 分片被清空,试图访问该分片中的 key 的 goroutine 开始分配内存,而先前的内存仍未完全释放,从而导致内存使用量激增和 OOM 崩溃。所以这种方法的性能不能随内核数量很好地扩展。
另外这种粗略的方式是以缓存数目作为 Cap 的,没有考虑每个 value 的大小。以缓存数目作为基准,是没法限制住内存大小的。如果高负载的业务,设置大的 Cap,极端的讲,每个 value 都非常大,几十个 MB,整体内存消耗可能上百 GB。如果是低负载的业务,设置很小的 Cap,极端情况,每个 value 特别小。总内存大小可能在 1 KB。这样看,内存上限和下限浮动太大了,无法折中限制。
欠缺的分为 2 部分,一部分是功能性,一部分是性能。功能性方面欠缺 TTL,持久化。TTL 是过期时间,到时间需要删除 key。持久化是将缓存中的数据保存至文件中,或者启动的时候从文件中读取。
性能方面欠缺的是高效的 hash 算法,高命中率,内存限制,可伸缩性。
高效的 hash 算法指的是类似 AES Hash,针对 CPU 是否支持 AES 指令集进行了判断,当 CPU 支持 AES 指令集的时候,它会选用 AES Hash 算法。一些高效的 hash 算法用汇编语言实现的。
高命中率方面,可以参考 BP-Wrapper: A System Framework Making Any Replacement Algorithms (Almost) Lock Contention Free 这篇论文,在这篇论文里面提出了 2 种方式:prefetching 和 batching。简单说一下 batching 的方式。在等待临界区之前,先填满 ring buffer。如该论文所述,借用 ring buffer 这种方式,几乎没有开销,从而大大降低了竞争。实现 ring buffer 可以考虑使用 sync. Pool 而不是其他的数据结构(切片,带区互斥锁等),原因是性能优势主要是由于线程本地存储的内部使用,而其他的数据结构没有这相关的 API。
内存限制。无限大的缓存实际上是不可能的。高速缓存必须有大小限制。如何制定一套高效的淘汰的策略就变的很关键。LRU 这个淘汰策略好么?针对不同的使用场景,LRU 并不是最好的,有些场景下 LFU 更加适合。这里有一篇论文 TinyLFU: A Highly Efficient Cache Admission Policy,这篇论文中讨论了一种高效缓存准入策略。TinyLFU 是一种与淘汰无关的准入策略,目的是在以很少的内存开销来提高命中率。主要思想是仅在新的 key 的估计值高于正要被逐出的 key 的估计值时才允许进入 Cache。当缓存达到容量时,每个新的 key 都应替换缓存中存在的一个或多个密钥。并且,传入 key 的估值应该比被淘汰出去的 key 估值高。否则新的 key 禁止进入缓存中。这样做也为了保证高命中率。
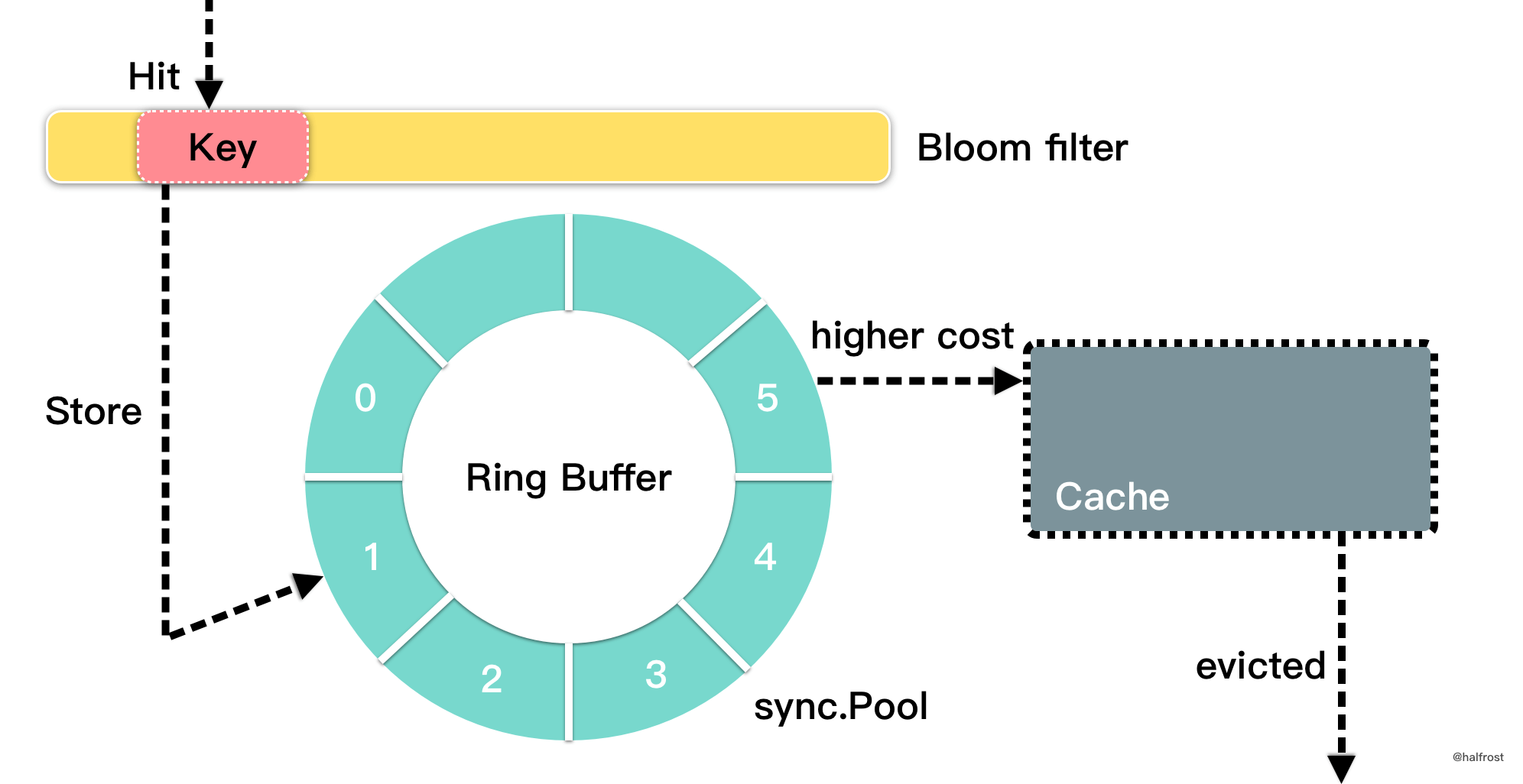
在将新 key 放入 TinyLFU 中之前,还可以使用 bloom 过滤器首先检查该密钥是否之前已被查看过。仅当 key 在布隆过滤器中已经存在时,才将其插入 TinyLFU。这是为了避免长时间不被看到的长尾键污染 TinyLFU。
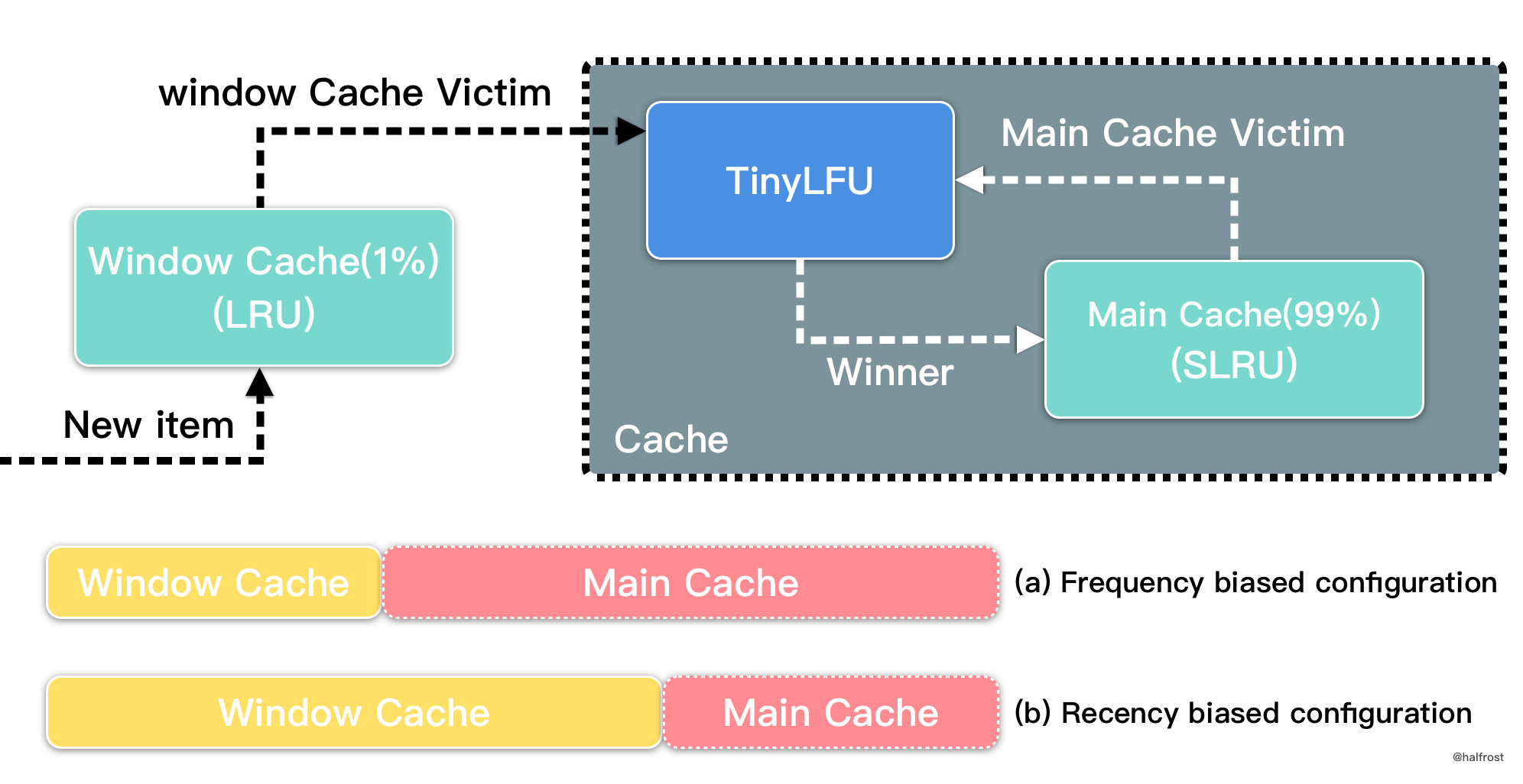
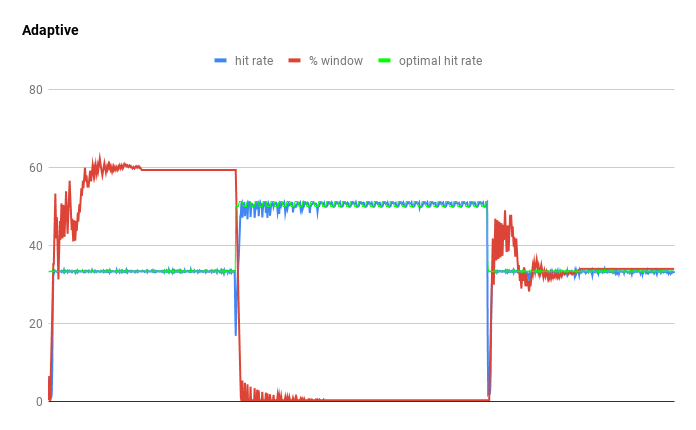
关于到底选择 LRU 还是 LFU 还是 LRU + LFU ,这个话题比较大,展开讨论又可以写好几篇新文章了。感兴趣的读者可以看看这篇论文,Adaptive Software Cache Management ,从标题上看,自适应的软件缓存管理,就能看出它在探讨了这个问题。论文的基本思想是在主缓存段之前放置一个 LRU “窗口”,并使用爬山技术自适应地调整窗口大小以最大化命中率。A high performance caching library for Java 8 — Caffeine 已经取得了很好的效果。
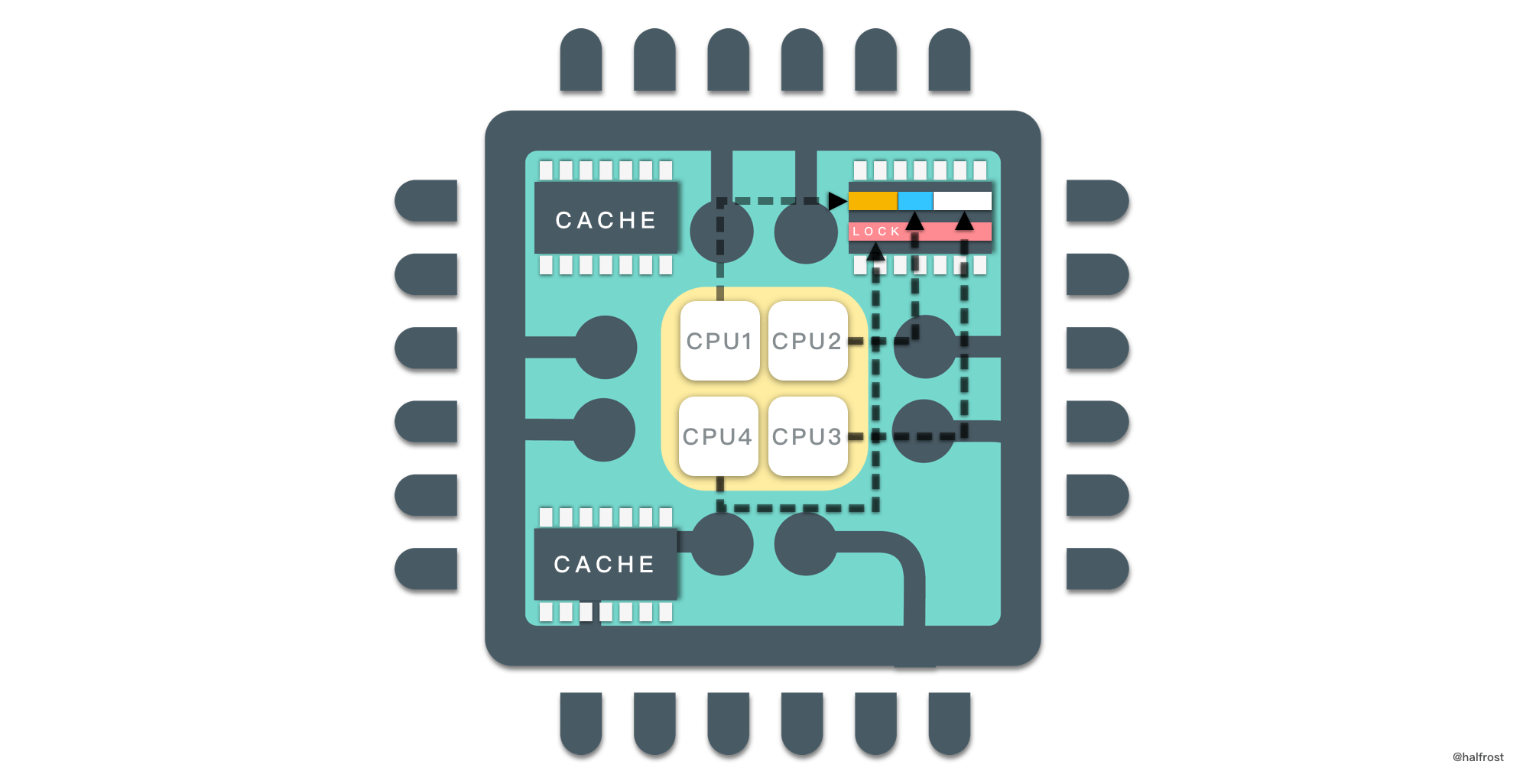
可伸缩性方面,选择合适的缓存大小,可以避免 False Sharing,在多核系统中,其中不同的原子计数器(每个 8 字节)位于同一高速缓存行(通常为 64 字节)中。对这些计数器之一进行的任何更新都会导致其他计数器被标记为无效。这将强制为拥有该高速缓存的所有其他核心重新加载高速缓存,从而在高速缓存行上创建写争用。为了实现可伸缩性,应该确保每个原子计数器完全占用完整的缓存行。因此,每个内核都在不同的缓存行上工作。
最后看看 Go 实现的几个开源 Cache 库。关于这些 Cache 的源码分析,本篇文章就不展开了。(有时间可能会单独再开一篇文章详解)。感兴趣的读者可以自己查阅源码。
bigcache,BigCache 根据 key 的哈希将数据分为 shards。每个分片都包含一个映射和一个 ring buffer。每当设置新元素时,它都会将该元素追加到相应分片的 ring buffer 中,并且缓冲区中的偏移量将存储在 map 中。如果同一元素被 Set 多次,则缓冲区中的先前条目将标记为无效。如果缓冲区太小,则将其扩展直到达到最大容量。每个 map 中的 key 都是一个 uint 32 hash,其值是一个 uint 32 指针,指向该值与元数据信息一起存储的缓冲区中的偏移量。如果存在哈希冲突,则 BigCache 会忽略前一个键并将当前键存储到映射中。预先分配较少,较大的缓冲区并使用 map[uint 32]uint 32 是避免承担 GC 扫描成本的好方法。
freecache,FreeCache 通过减少指针数量避免了 GC 开销。无论其中存储了多少条目,都只有 512 个指针。通过 key 的哈希值将数据集分割为 256 个段。将新 key 添加到高速缓存时,将使用 key 哈希值的低八位来标识段 ID。每个段只有两个指针,一个是存储 key 和 value 的 ring buffer,另一个是用于查找条目的索引 slice。数据附加到 ring buffer 中,偏移量存储到排序 slice 中。如果 ring buffer 没有足够的空间,则使用修改后的 LRU 策略从 ring buffer 的开头开始,在该段中淘汰 key。如果条目的最后访问时间小于段的平均访问时间,则从 ring buffer 中删除该条目。要在 Get 的高速缓存中查找条目,请在相应插槽 slot 中的排序数组中执行二进制搜索。此外还有一个加速的优化,使用 key 的哈希的 LSB 9-16 选择一个插槽 slot。将数据划分为多个插槽 slot 有助于减少在缓存中查找键时的搜索空间。每个段都有自己的锁,因此它支持高并发访问。
groupCache,groupcache 是一个分布式的缓存和缓存填充库,在许多情况下可以替代 memcached。在许多情况下甚至可以用来替代内存缓存节点池。groupcache 实现原理和本文在上一章节中实现的方式是一摸一样的。
fastcache,fastcache 并没有缓存过期的概念。仅在高速缓存大小溢出时才从高速缓存中淘汰 key 值。key 的截止期限可以存储在该值内,以实现缓存过期。fastcache 缓存由许多 buckets 组成,每个 buckets 都有自己的锁。这有助于扩展多核 CPU 的性能,因为多个 CPU 可以同时访问不同的 buckets。每个 buckets 均由一个 hash(key)->(key,value)的映射和 64 KB 大小的字节 slice(块)组成,这些字节 slice 存储已编码的(key,value)。每个 buckets 仅包含 chunksCount 个指针。例如,64 GB 缓存将包含大约 1 M 指针,而大小相似的 map[string][]byte 将包含 1 B 指针,用于小的 key 和 value。这样做可以节约巨大的 GC 开销。与每个 bucket 中的单个 chunk 相比,64 KB 大小的 chunk 块减少了内存碎片和总内存使用量。如果可能,将大 chunk 块分配在堆外。这样做可以减少了总内存使用量,因为 GC 无需要 GOGC 调整即可以更频繁地收集未使用的内存。
ristretto,ristretto 拥有非常优秀的缓存命中率。淘汰策略采用简单的 LFU,性能与 LRU 相当,并且在搜索和数据库跟踪上具有更好的性能。存入策略采用 TinyLFU 策略,它几乎没有内存开销(每个计数器 12 位)。淘汰策略根据代价值判断,任何代价值大的 key 都可以淘汰多个代价值较小的 key(代价值可以是自定义的衡量标准)。
以下是这几个库的性能曲线图:
在一小时内对 CODASYL 数据库的引用:

在商业站点上运行的数据库服务器,该服务器在商业数据库之上运行 ERP 应用程序:

循环访问模式:

大型商业搜索引擎响应各种 Web 搜索请求而启动的磁盘读取访问:

吞吐量:



推荐阅读
BP-Wrapper: A System Framework Making Any
Replacement Algorithms (Almost) Lock Contention Free
Adaptive Software Cache Management
TinyLFU: A Highly Efficient Cache Admission Policy
LIRS: An Efficient Low Inter-reference Recency Set Replacement Policy to Improve Buffer Cache Performance
ARC: A Self-Tuning, Low Overhead Replacement Cache